
Dictionary底层源码剖析
- Unity
- 2024-06-17
- 1116热度
- 0评论
Dictionary字典型数据结构是以关键字Key值和Value值进行一一映射,Key的类型并没有做任何限制,可以是整数,也可以是字符串,甚至是实例对象。Dictionary的实验原理,有两个关键算法,Hash算法和解决Hash冲突的拉链法,key值和value值的映射关系就是通过Hash函数来建立的。
一、实现原理
1.1 Hash函数
Dictionary会针对每个Key值加入容器的元素都进行一次Hash(哈希)运算操作,从而找到自己存放的位置。Hash函数可以有很多种算法,最简单的可以认为是取余操作。
对于实例对象和字符串来说,它们没有直接的数字作为hash标准,因此它们需要通过内存地址计算一个Hash值,计算这个内存对象的函数就叫HashCode,它是基于内存地址来计算得到的结果,我们也可以通过重载HashCode()来设计我们自定义的Hash值计算方法。
1.2 Hash冲突
当不同的Key值进行Hash计算后,得到的结果可能是同一Hash地址。HashFunc(key1) == HashFunc(key2),这种现象被成为Hash冲突。在处理Hash冲突的方法中,有开放寻址法、拉链法、再Hash法等,而Dictionary使用的是拉链法(又称链地址法)。
拉链法的原理: 将所有具有相同哈希值的元素链接在一起,形成一个链表。当发生冲突时,新的元素会被添加到链表的末尾,链表的每一个元素都包含一个指向实际数据的指针和一个指向下一个元素的指针。
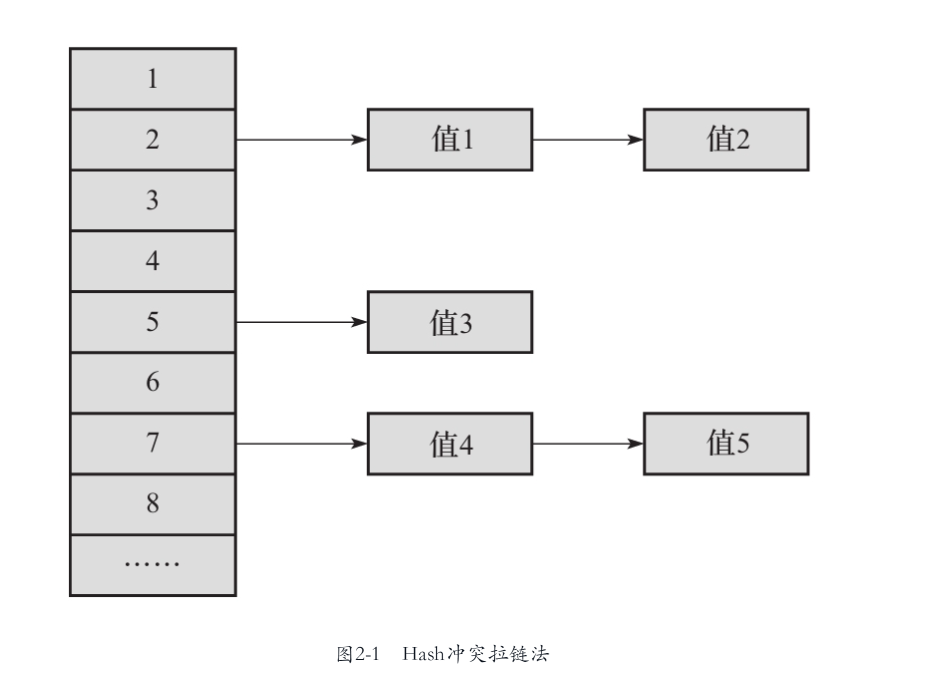
二、Dictionary接口
2.1 变量定义
- Dictionary:底层的数据结构为哈希表,而哈希表的数组结构为数组。
public class Dictionary<TKey, TValue> : IDictionary<TKey, TValue>, IDictionary, IReadOnlyDictionary<TKey, TValue>,
ISerializable, IDeserializationCallback
{
private struct Entry
{
public uint hashCode; // 哈希值
public int next; // 下一个元素的下标索引
public TKey key; // 存放元素的键
public TValue value; // 存放元素的值
}
private int[] buckets; // 桶,存放的数值为entries数组元素的下标索引
private Entry[] entries; // 桶对应的链表
private int count; // 元素个数
private int version; // 版本号,防止迭代的时候集合被修改
private int freeList; // 桶对应数组中被删除Entry的下标索引(单链表)
private int freeCount; // 记录被删除的Entry的数量
private IEqualityComparer<TKey> comparer; // 比较器
private KeyCollection keys; // 存放key的集合
private ValueCollection values; // 存放value的集合
private Object _syncRoot;
}2.2 Add接口
public void Add(TKey key, TValue value)
{
Insert(key, value, true);
}
private void Initialize(int capacity)
{
int size = HashHelpers.GetPrime(capacity); // size大小
buckets = new int[size]; // 创建桶数组
for (int i = 0; i<buckets.Length; i++) buckets[i] = -1; // buckets默认全为-1
entries = new Entry[size]; // 创建Entry实体数组
freeList = -1; // freeList默认为-1
}
private void Insert(TKey key, TValue value, bool add)
{
if( key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets == null) Initialize(0); // 对数据结构进行构造
// 对Key进行哈希操作
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;
// 通过地址找到桶对应的链表,
for (int i = buckets[targetBucket]; i>= 0; i = entries[i].next)
{
// 如果存在则修改
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
{
// 添加相同的键值对,会抛出异常
if (add)
{
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
entries[i].value = value;
version++;
return;
}
}
// 桶的index
int index;
// 如果被删除剩余数量足够
if (freeCount > 0)
{
index = freeList;
// freeList等于删除单链表
freeList = entries[index].next;
freeCount--;
}
else
{
// 被删除数量不足够,判断数组数量是否已满
if (count == entries.Length)
{
// 扩容
Resize();
// 重新判断哈希值
targetBucket = hashCode % buckets.Length;
}
// index等于count值
index = count;
count++;
}
// 进行赋值操作
entries[index].hashCode = hashCode;
entries[index].next = buckets[targetBucket];
entries[index].key = key;
entries[index].value = value;
buckets[targetBucket] = index;
version++;
}Add接口其实就是Insert的代理, Insert(key, value, true)
在加入数据前,首先需要对数据结构进行构造,其代码如下:
if (buckets == null) Initialize(0); // 对数据结构进行构造
private void Initialize(int capacity)
{
int size = HashHelpers.GetPrime(capacity); // size大小
buckets = new int[size]; // 创建桶数组
for (int i = 0; i<buckets.Length; i++) buckets[i] = -1; // buckets默认全为-1
entries = new Entry[size]; // 创建Entry实体数组
freeList = -1; // freeList默认为-1
}
public class HashHelpers
{
public static readonly int[] primes = {
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239,
293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013,
8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523,
108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827,
807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471,
7199369};
public static int GetPrime(int min)
{
if (min<0)
throw new ArgumentException(
Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
// 找到大于需要数量的最小质数
for (int i = 0; i<primes.Length; i++)
{
int prime = primes[i];
if (prime>= min) return prime;
}
// 如果在我们的预定义表之外,则做硬计算
for (int i = (min | 1); i<Int32.MaxValue;i+=2)
{
if (IsPrime(i) && ((i - 1) % Hashtable.HashPrime != 0))
return i;
}
return min;
}
// 返回要增长到的Hash表的大小
public static int ExpandPrime(int oldSize)
{
int newSize = 2 * oldSize;
// 在遇到容量溢出之前,允许Hash表增长到最大可能的大小(约2G个元素)
// 请注意,即使(item.Length)由于(uint)强制转换而溢出,此检查仍然有效
if ((uint)newSize>MaxPrimeArrayLength && MaxPrimeArrayLength>oldSize)
{
Contract.Assert( MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength),
"Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
return GetPrime(newSize);
}
初始化数组大小时,会通过HashHelper类的GetPrime()函数,返回一个需要的size最小质数值。
GetPrime():表示当需要的数量小于primes某个单元格的数字时返回该数字, 即大于需要数量的primes数组中的最小质数。
ExpandPrimes():数组扩容, 当前容量的2倍的primes最小质数值。即3->7->17->37(大于34的最小质数)->89(大于74的最小质数)->...
初始化数组后,会对关键字Key做Hash操作,从而获得地址索引
// 对Key进行哈希操作
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;当调用函数获得hash值后,还对hash地址进行取余操作,以确保索引地址落在Dictionary数组长度范围内,而不会溢出。
接着在对指定数组进行单元格内的链表执行遍历操作,如果找到相同的键值对则抛出异常,然后在进行赋值操作,赋值操作会先判断之前是否有释放的entry,如果有的话对之前的entry进行赋值,如果没有则判断当前容量是否足够,如果不够则进行扩容操作。扩容操作代码如下:
private void Resize()
{
// 新size为ExpandPrime(count)
Resize(HashHelpers.ExpandPrime(count), false);
}
private void Resize(int newSize, bool forceNewHashCodes)
{
Contract.Assert(newSize >= entries.Length);
int[] newBuckets = new int[newSize]; // 重建桶
for (int i = 0; i < newBuckets.Length; i++) newBuckets[i] = -1; // 初始化桶
Entry[] newEntries = new Entry[newSize];
Array.Copy(entries, 0, newEntries, 0, count); // 将之前的元素拷贝到新数组中
if(forceNewHashCodes) // 是否强制重算HashCode值
{
for (int i = 0; i < count; i++)
{
if(newEntries[i].hashCode != -1)
{
newEntries[i].hashCode = (comparer.GetHashCode(newEntries[i].key) & 0x7FFFFFFF);
}
}
}
// 重置桶
for (int i = 0; i < count; i++)
{
if (newEntries[i].hashCode >= 0)
{
int bucket = newEntries[i].hashCode % newSize;
newEntries[i].next = newBuckets[bucket];
newBuckets[bucket] = i;
}
}
buckets = newBuckets;
entries = newEntries;
}2.3 Remove接口
public bool Remove(TKey key)
{
if(key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null)
{
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int bucket = hashCode % buckets.Length;
int last = -1;
for (int i = buckets[bucket]; i>= 0; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
{
if (last<0)
{
buckets[bucket] = entries[i].next;
}
else
{
// 如果删除的元素在链表中间,上一个元素和下一个元素相连,防止单链表中断
entries[last].next = entries[i].next;
}
entries[i].hashCode = -1;
entries[i].next = freeList; // 删除的链表下标
// 赋默认值
entries[i].key = default(TKey);
entries[i].value = default(TValue);
freeList = i;
freeCount++;
version++;
return true;
}
}
}
return false;
}Remove接口相对于Add接口简单一点,先使用Hash函数获得Hash值,再执行余操作,确定索引值落在数组范围内,从Hash索引地址开始查找链表中的值,查找冲突链表中元素的Key值是否与需要移除的Key值相同,相同则进行删除操作。
2.4 ContainKey、TryGetValue接口
public bool ContainsKey(TKey key)
{
return FindEntry(key)>= 0;
}
public bool TryGetValue(TKey key, out TValue value)
{
int i = FindEntry(key);
if (i>= 0) {
value = entries[i].value;
return true;
}
value = default(TValue);
return false;
}
private int FindEntry(TKey key)
{
if( key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
for (int i = buckets[hashCode % buckets.Length]; i>= 0; i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key,key)) return i;
}
}
return -1;
}两者主要都是使用FindEntry()函数,使用Key值得到的Hash值地址开始查找,查看所有冲突链表中是否有与Key值相同的值,若找到,即刻返回该索引地址。
三、总结
从源码剖析来看,Hash冲突的拉链法贯穿了整个底层数据结构。因此Hash函数是关键,Hash函数的好坏直接决定了效率的高低。Hash函数源码就不在这解释了,因为我看不懂😂,
了解了Dictionary的内部构造和运作机制,可以知道它是有数组构成,并由Hash函数完成地址构建,并由拉链法解析哈希冲突。
从效率上看,同List一样,最好在实例化对象,即新建时,确定大致数量,这样会使得内存分配次数减少,另外,使用数值方式作为键值比使用类实例的方式更高效,因为类对象实例的Hash值通常都由内存地址再计算得到。从内存操作上看,其大小以3→7→17→37→…的速度(每次增加2倍多)增长,删除时,并不缩减内存。
Dictionary也是线性不安全的,因此在多线程访问的时候,需要自行加lock处理。